ESLint 오류 해결기 - await을 for...of 반복문에서 사용하지 않기
· 약 4분


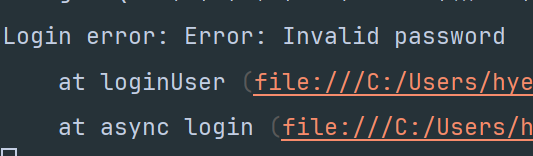
ESLint에서 다음과 같은 두 가지 오류가 발생했습니다:
no-restricted-syntax:for...of반복문을 사용할 수 없다는 경고no-await-in-loop: 반복문 내에서await을 사용하면 안 된다는 경고 이 오류를 해결하려면 어떻게 해야 할지에 대해 고민한 결과,for...of루프 대신Promise.all을 사용하여 비동기 작업을 병렬로 처리하는 방법을 적용할 수 있었습니다. 이번 포스팅에서는 이 문제를 해결하기 위해 사용한 방법을 공유하려고 합니다.
🙄 문제 원인
ESLint에서 for...of 루프에서 await을 사용할 때 오류가 발생합니다. 두 가지 규칙이 겹치는 문제로, for...of와 같은 반복문을 사용할 수 없다는 규칙(no-restricted-syntax)과 반복문 안에서 await을 사용하는 것을 금지하는 규칙(no-await-in-loop)이 문제를 일으켰습니다.
🤗 해결 방법
이 문제를 해결하기 위해 **Promise.all**을 사용하여 비동기 작업을 병렬로 처리하는 방법을 적용했습니다. ��병렬 처리로 각 작업이 독립적으로 실행되므로, 반복문 내에서 await을 사용할 필요가 없어집니다.
🕶️ 수정 전 코드
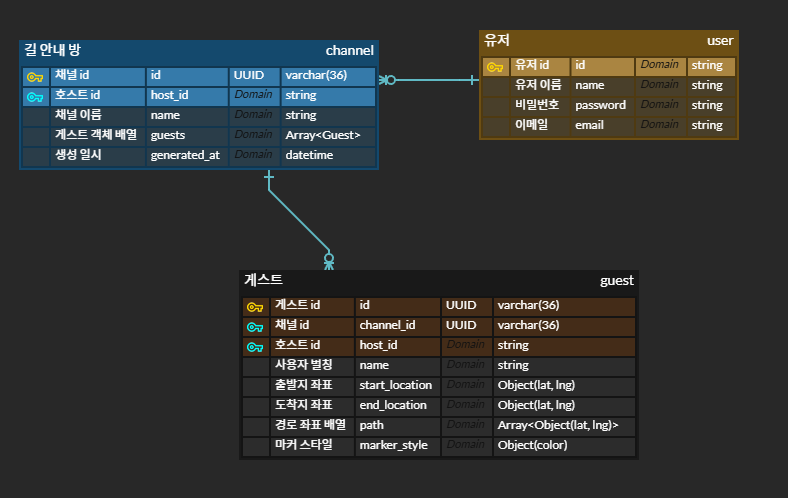
for (const guest of guests) {
const { name, start_location, end_location, path, marker_style } = guest;
await addGuestInDB(channel.id, name, start_location, end_location, path, marker_style, host_id);
}
위와 같은 코드에서는 for...of 반복문 내에서 await을 사용하고 있어 ESLint 경고가 발생합니다.
🕶️ 수정 후 코드
const guestPromises = guests.map((guest) => {
const { name, start_location, end_location, path, marker_style } = guest;
return addGuestInDB(channel.id, name, start_location, end_location, path, marker_style, host_id);
});
// Promise.all을 사용하여 병렬로 실행
await Promise.all(guestPromises);
✨설명
map:guests배열의 각 요소를 순회하면서 비동기 작업(addGuestInDB)을 반환합니다.map은 새로운 배열을 반환하는데, 이 배열은 각 비동기 작업을Promise객체로 감쌉니다.Promise.all:Promise.all을 사용하여 모든Promise가 해결될 때까지 기다립니다. 이로 인해 병렬로 모든 비동기 작업이 실행되며, 반복문 내에서await을 사용할 필요가 없어집니다.
🖼️ 장점
- 성능 최적화: 모든 비동기 작업을 병렬로 처리하기 때문에
for...of보다 더 효율적으로 실행됩니다. - ESLint 오류 해결:
for...of와await을 조합하는 방식에서 발생하는 ESLint 오류를 해결할 수 있습니다. - 가독성 개선:
map과Promise.all을 사용하여 코드를 더 직관적이고 간결하게 만들 수 있습니다.
🛒 결론
ESLint에서 for...of와 await을 동시에 사용할 때 발생하는 경고를 해결하기 위해, 반복문을 map과 Promise.all로 대체하여 병렬로 비동기 작업을 처리하는 방법을 적용했습니다. 이 방법은 성능 최적화와 코드 가독성 개선에도 도움을 주며, ESLint 오류도 해결할 수 있습니다.









 저조차 믿기지 않는 폴더구조였지만…… 제가 드래그를 잘못해서 복사가 되었는지…. 정말 왜인지 모르겠지만
저조차 믿기지 않는 폴더구조였지만…… 제가 드래그를 잘못해서 복사가 되었는지…. 정말 왜인지 모르겠지만